Codice genetico
Che cos'è il codice genetico?
Il dogma centrale della biologia asserisce che l'informazione contenuta nella sequenza di nucleotidi del DNA (la molecola che custodisce tutte le informazioni per la struttura ed il funzionamento di tutte le nostre cellule) deve essere copiata fedelmente da una cellula madre alle due cellule figlie nella mitosi, deve essere trascritta in molecole di RNA e successivamente quest'ultimo deve essere tradotto in proteine.
Le proteine svolgono nella cellula diverse funzioni (strutturali, informazionali, di regolazione, ecc) e sono gli operai (enzimi) per far avvenire qualunque evento cellulare.
Per molti anni il passaggio dell'informazione dagli acidi nucleici alle proteine attraverso il dogma centrale della biologia (vedi figura) è stato un punto fermo per i biologi ed anche oggi che alcune scoperte come i miRNA vanno controcorrente rispetto ad esso, il suo valore nello studio della biologia molecolare non è discusso.
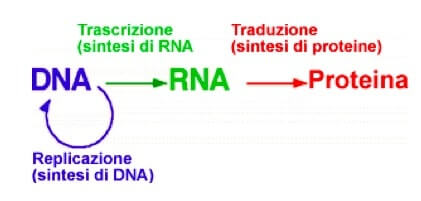
Il Dogma centrale della Biologia.
Secondo il dogma l'informazione è contenuta nel DNA che è in grado di replicarsi in maniera che essa sia conservata da una generazione all'altra.
L'informazione contenuta nel DNA è quella necessaria per la produzione di una proteina. Per sintetizzare le proteine è necessario che l'informazione esca dal nucleo (dove è custodito il DNA) e raggiunga il citoplasma: per far ciò il DNA è trascritto in RNA (acido ribonucleico), in un tipo particolare di RNA, il messaggero (mRNA) che viene infine tradotto in proteine all'interno dei ribosomi (corpuscoli presenti nel citoplasma in cui avviene l'assemblaggio degli amminoacidi in proteina).
L'informazione contenuta negli acidi nucleici deve dunque essere tradotta in una sequenza di amminoacidi che costituiscono la singola proteina. Il codice che consente di trasformare una sequenza di nucleotidi in una sequenza di amminoacidi è detto codice genetico.
Il codice genetico
Il processo della sintesi proteica prevede che l'informazione contenuta nella sequenza di nucleotidi degli acidi nucleici sia convertita in una sequenza di amminoacidi, ovvero in una proteina. Occorre dunque tradurre il codice genetico in proteico.
Per effettuare la sintesi proteica è necessario un tipo particolare di RNA, il messaggero (mRNA) che lascia il nucleo e si porta nel citosol. Qui viene inserito nei ribosomi, corpuscoli liberi nel citosol oppure legati al reticolo endoplasmatico rugoso costituiti da RNA (ribosomiale) e proteine, nei quali avviene l'assembramento degli aminoacidi in proteina.
I biologi hanno cercato di capire come l'informazione contenuta nei nucleotidi potesse trasformarsi, potesse essere tradotta, in una sequenza di amminoacidi ed hanno inizialmente ipotizzato che un singolo nucleotide codificasse per un amminoacido.
In questo modo tuttavia il codice genetico avrebbe codificato solo per quattro dei venti amminoacidi esistenti nella struttura delle proteine. In maniera analoga si è allora ipotizzato occorressero due nucleotidi per codificare un amminoacido, in tal modo le possibili combinazioni sono date da 4 (numero di nucleotidi) elevato a 2 (numero dei membri della coppia) ovvero 16.
Sedici combinazioni non sono ancora sufficienti a codificare per 20 amminoacidi, dunque l'ipotesi successiva è stata di 3 nucleotidi per ogni amminoacido: 43 = 64.
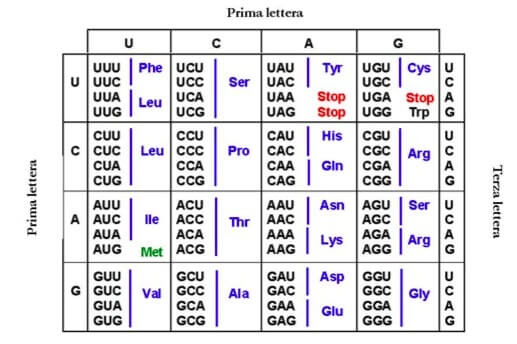
Il codice genetico: si noti che le triplette che codificano per lo stesso amminoacido hanno in comune i primi due nucleotidi. STOP indica le tre triplette (codoni) che indicano la terminazione della traduzione.
Sessantaquattro è un numero di combinazioni possibili sufficiente per codificare i 20 amminoacidi, anzi si avranno combinazioni (triplette) in più.
Tale ipotesi così come tutto il processo della sintesi proteica sono stati validati da evidenze scientifiche come vuole il metodo scientifico: ovvero si parte da una ipotesi per spiegare un fenomeno osservato e si allestiscono esperimenti al fine di verificare o confutare l'ipotesi.
Pertanto l'analisi accurata dei risultati fenotipici di esperimenti di mutazioni puntiformi, di delezioni o inserzioni, ha dimostrato che un gruppo di nucleotidi, la tripletta, è in grado di codificare per un singolo amminoacido.
Altre evidenze sperimentali mostravano inoltre che l'mRNA viene letto in ordine lineare: la lettura parte cioè da un'estremità e giunge all'altra, l'mRNA è letto come fosse un nastro che viene fatto scorrere all'interno del ribosoma, al quale si associa all'inizio del processo di traduzione.
Crick (uno dei ricercatori che ha scoperto la struttura della doppia elica del DNA) avanzò l'ipotesi che per la traduzione del codice genetico siano necessarie delle molecole, che oggi sappiamo essere di RNA, in grado di legarsi ad ognuno dei 20 aminoacidi e in grado di riconoscere la tripletta di nucleotidi.
Sino al 1960 non è stato possibile capire come l'informazione contenuta nel DNA potesse trasformarsi nelle istruzioni per produrre una proteina poiché non si conosceva l'esistenza dell'RNA messaggero che fu isolato appunto in quell'anno.
Solo dopo tale scoperta si poté ipotizzare la struttura del macchinario molecolare in grado di operare la traduzione del messaggio da nucleotidico ad amminoacidico.
Con la scoperta del messaggero fu possibile individuare che il DNA venisse prima trascritto in un molecola di mRNA in grado di lasciare il nucleo e raggiungere il citoplasma, in particolare la sede del macchinario molecolare per la sintesi delle proteine: il ribosoma, un corpuscolo costituito da proteine e da una famiglia di RNA definita ribosomiale costituita da molecole brevi dotati di attività catalitica.
Data la scoperta del messaggero fu chiaro che il codice genetico venisse tradotto su questa molecola all'interno dei ribosomi e non direttamente sul DNA a livello nucleare.
Nel 1961 utilizzando degli RNA messaggeri sintetici, in particolare costituiti da un singolo ribonucleotide ripetuto o comunque sequenze note di ribonucleotidi fu possibile decifrare il codice genetico in una serie di esperimenti in vitro.
I polinucleotidi sintetici si devono a L. Heppel e M. Singer, è stato così possibile utilizzarli come "stampo" per la sintesi proteica ideata grazie a J.H. Matthaei in vitro in un sistema privo di cellule capace di iniziare la sintesi non appena vi fosse aggiunto un messaggero.
Quando il polinucleotide era costituito solo da una base (ad esempio l'uracile) si doveva ottenere un polipeptide con un unico amminoacido ripetuto (nell'esempio la fenilalanina).
Dall'analisi della composizione in amminoacidi dei polipeptidi così prodotti dai messaggeri sintetici, è stato possibile individuare tutti i codoni ovvero le triplette del codice genetico.
Qualche anno dopo, nel 1964 si giunse anche alla dimostrazione che erano implicati nel processo di sintesi proteica anche i tRNA che riconoscono il codone del messaggero e sono legati ad uno specifico amminoacido.
Alcuni codoni erano risultati non codificare per nessun amminoacido e furono Crick e Brennet nel 1967 ad ipotizzare prima e a dimostrare dopo con esperimenti di mutazioni di tali codoni, che si trattasse dei cosiddetti codoni "di stop" ovvero i segnali per la terminazione della sintesi del polipeptide.
I codoni di stop non sono riconosciuti e legati da nessun tRNA ma da specifiche proteine di rilascio che inducono appunto il rilascio della proteina neo sintetizzata dal ribosoma.
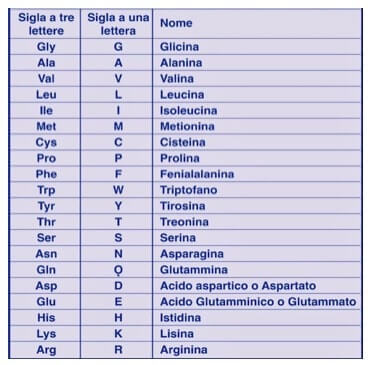
I codici a una e tre lettere per i singoli amminoacidi.
Il codice genetico è degenerato
Osservando la tabella nella quale abbiamo riportato il codice genetico, si può notare che per molti amminoacidi è segnato più di un codone (tripletta), per questo motivo si dice che il codice è degenerato.
In particolare, alo scopo di ridurre al minimo la possibilità di inserire errori nel processo della sintesi proteica, quando un amminoacido è codificato da più di una tripletta i primi due nucleotidi sono fondamentali mentre il terzo può essere ad esempio un uracile o una citosina senza inficiare la scelta del corretto amminoacido.
Una curiosità: i codoni con nucleotidi pirimidinici in seconda posizione codificano prevalentemente per amminoacidi idrofobici, mentre quelli con purine nella medesima posizione codificano per amminoacidi prevalentemente polari.
Di conseguenza di quanto detto, un'eventuale mutazione nella terza lettera del codone porterà generalmente allo stesso amminoacido, mentre nella seconda porterà alla sostituzione di amminoacidi simili e la stessa cosa si può dire della prima posizione.
Il codice è dunque stato ottimizzato dall'evoluzione per minimizzare gli effetti delle mutazioni sulla struttura delle proteine e preservare di conseguenza la funzione.
Link correlati:
Che cos'è il DNA ricombinante?
Che cos'è il genotipo?
Che cosa sono il ciclo ciclo litico e lisogeno?
Che cos'è la clonazione?
Studia con noi